Parallel execution in Oracle is a powerful feature designed to accelerate large data operations by distributing work across multiple CPU cores. But when misused or left unchecked, it can lead to serious performance bottlenecks—including 100% CPU utilization that brings your database to its knees.
What Is a Parallel Query?
A parallel query breaks a SQL operation into smaller chunks and executes them simultaneously using Parallel Execution (PX) servers. This is ideal for:
- Full table scans on large datasets
- Complex joins and aggregations
- Data warehouse workloads
How to Check Running Parallel Queries
SELECT
px.qcsid AS qc_sid,
s.sid,
s.serial#,
px.req_degree AS requested_dop,
px.degree AS actual_dop,
s.sql_id,
s.status,
s.username,
s.program
FROM
gv$px_session px
JOIN
gv$session s ON px.sid = s.sid AND px.serial# = s.serial# AND px.inst_id = s.inst_id
WHERE
s.status = 'ACTIVE'
ORDER BY
px.qcsid;
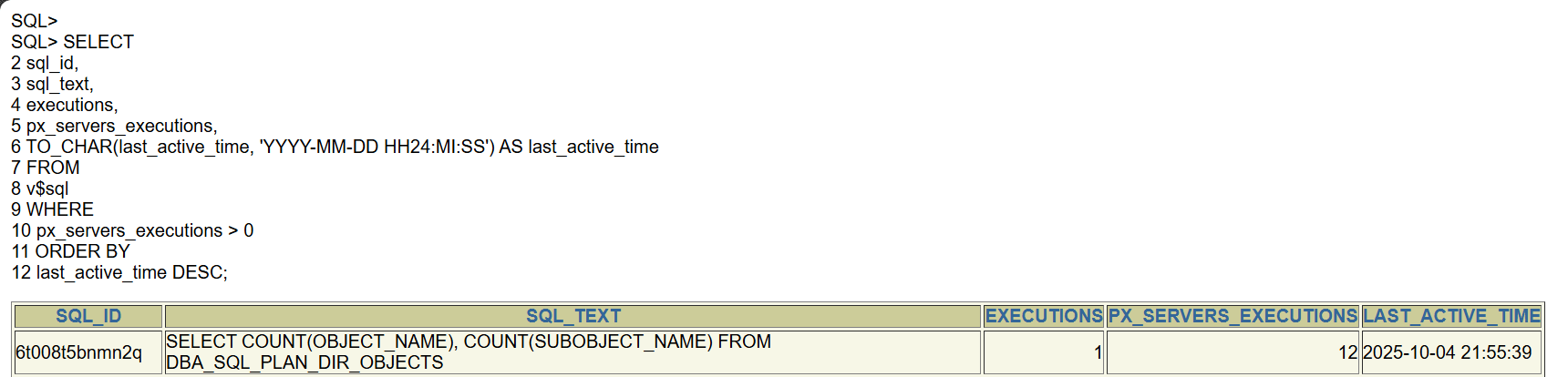
How to Find Previously Executed Parallel Queries
SELECT
sql_id,
sql_text,
executions,
px_servers_executions,
TO_CHAR(last_active_time, 'YYYY-MM-DD HH24:MI:SS') AS last_active_time
FROM
v$sql
WHERE
px_servers_executions > 0
ORDER BY
last_active_time DESC;
Why Parallel Queries Can Cause 100% CPU
Each parallel query can spawn N × DOP processes. For example, a query with DOP 8 may use 8 PX slaves plus a QC. Multiply that by several concurrent queries, and you can easily exhaust all CPU cores.
Symptoms include:
- High system load
- Slow response times
- CPU pegged at 100%
- OLTP workloads suffering
How to Reduce Parallel Query Usage
Here are practical strategies to control parallelism:
1. Limit Degree of Parallelism (DOP)
Use session or table-level controls:
ALTER SESSION FORCE PARALLEL QUERY PARALLEL 2;
ALTER SESSION DISABLE PARALLEL QUERY;
--object level table or index
ALTER TABLE sales PARALLEL(DEGREE 2);2. Use Oracle Resource Manager
BEGIN
DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(
plan => 'LIMITED_CPU_PLAN',
group_or_subplan => 'LOW_PRIORITY_GROUP',
parallel_degree_limit_p1 => 2
);
END;3. Avoid Parallel Hints in OLTP
Remove /*+ PARALLEL */ hints from frequently executed queries, especially in transactional systems.
4. Limit the CPU usage by define limit in PARALLEL_DEGREE_LIMIT
At system level, Edit the Parameter to Half of the CPU you have in your system suppose you have 16 CPU then limit to 8
-- Limit DOP to 8
ALTER SYSTEM SET PARALLEL_DEGREE_LIMIT = 8;
-- Let Oracle decide based on CPU
ALTER SYSTEM SET PARALLEL_DEGREE_LIMIT = CPU;Export Parallel Query Report in HTML
Generate a report using SQL*Plus:
SET MARKUP HTML ON SPOOL ON ENTMAP OFF
SPOOL parallel_sql_report.html
SELECT
sql_id,
sql_text,
executions,
px_servers_executions,
TO_CHAR(last_active_time, 'YYYY-MM-DD HH24:MI:SS') AS last_active_time
FROM
v$sql
WHERE
px_servers_executions > 0
ORDER BY
last_active_time DESC;
SPOOL OFF
SET MARKUP HTML OFF