Understanding on Execution Plan
An Execution Plan shows the detailed Steps necessary to execute a SQL Statement. These steps are expressed as a set of database operators that utilize rows. The tabular representation is a top-down, left-to-right traversal of the execution tree.
Note: When you read a plan tree you should start from the bottom left and work across and then up.
Display Execution Plan in Oracle
EXPLAIN PLAN command – This displays an execution plan for a SQL statement without actually executing the statement.
DBMS_XPLAN package: is a function which can display as little (high-level) or as much (low-level) details.
It’s having following parameter for high level or low level details
BASIC: The plan includes only the ID, operation, and the object name columns.
Example: Used following SQL Queries for find the Execution plan for all three parameters:

Explain plan for select empno, ename, dname from emp a, dept b where a.deptno = b.deptno;
Select plan_table_output from table(dbms_xplan.display('plan_table',null,'basic'));

TYPICAL: Includes the information shown in BASIC plus additional optimizer-related internal information such as cost, cardinality estimates, etc. This information is shown for every operation in the plan and represents what the optimizer thinks is the operation cost, the number of rows produced, etc. It also shows the predicates evaluated by each operation. There are two types of predicates: ACCESS and FILTER. The ACCESS predicates for an index are used to fetch the relevant blocks by applying search criteria to the appropriate columns. The FILTER predicates are evaluated after the blocks have been fetched.
Select plan_table_output from table(dbms_xplan.display('plan_table',null,'typical'));
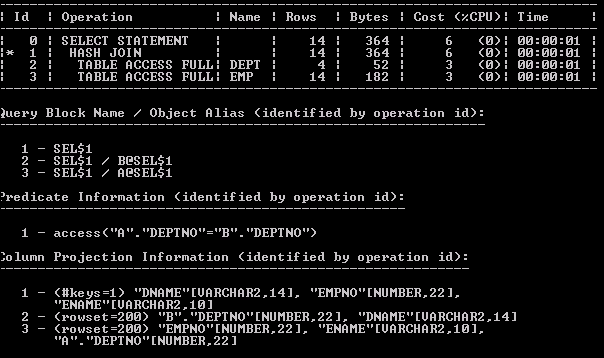
All: Includes the information shown in TYPICAL plus the lists of expressions (columns) produced by every operation, the hint alias and query block names where the operation belongs (the outline information). The last two pieces of information can be used as arguments to add hints to the statement.
Select plan_table_output from table(dbms_xplan.display('plan_table',null,'all'));
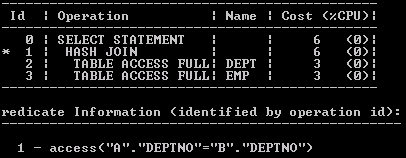
You can also customized BASIC plan output with selected options PREDICATE and COST the method by giving name as below:
SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('plan_table',null,'basic +predicate +cost'));
How the Optimizer go for best Execution Plan.
The Oracle Optimizer is a cost-based optimizer. The execution plan selected for a SQL statement is just one of the many alternative execution plans considered by the Optimizer. The Optimizer selects the execution plan with the lowest cost, where cost represents the estimated resource usage for that plan. The lower the cost the more efficient the plan is expected to be.
Example:
Explain plan for select empno, ename, dname from emp a, dept b where a.deptno = b.deptno;
On checking the query without Index:
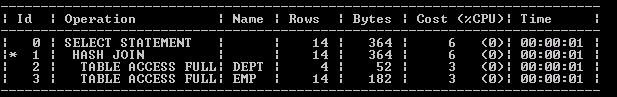
Executed the upper query again after making the index on DEPT table.
Create index on DEPT_IDX on DEPT (DEPTNO);
Then Oracle Optimizer automatically picks the execution plan with lower cost

In order to determine if you are looking at a good execution plan or not, you need to understand how the Optimizer determined the plan in the first place
The components to assess are:
- Cardinality– Estimate of the number of rows coming out of each of the operations.
- Access method – The way in which the data is being accessed, via either a table scan or index access.
- Join method – The method (e.g., hash, sort-merge, etc.) used to join tables with each other.
- Join type – The type of join (e.g., outer, anti, semi, etc.).
Cardinality:
The cardinality is the estimated number of rows that will be returned by each operation. The Optimizer determines the cardinality for each operation based on a complex set of formulas that use both table and column level statistics as input.
For Better Cardinality result you need to update the stats of the table and column
Example:
Exec DBMS_STATS.GATHER_TABLE_STATS('HR','EMPLOYEES', method_opt=>'FOR COLUMNS SIZE 254 JOB_ID');
Access Method:
The access method shows how the data will be accessed from each table (or index). Common access methods:
Full Table Scan: Reads all rows from a table and filters out those that do not meet the where clause. A full table scan is selected if large portion of the rows in the table must be accessed, no indexes exist or the ones present can’t be used or if the cost is the lowest.
Solution to avoid full table scan:
Check the table having index on the column which is used in where clauses.
Table access by ROWID: The rowid of a row specifies the data file, the data block within that file, and the location of the row within that block. Oracle first fetch the ROWID by full or index scan then locates each selected row in the table based on its rowid and does a row-by-row access.
Index range scan: Oracle accesses adjacent index entries and then uses the ROWID values in the index to retrieve the corresponding rows from the table. It will be used when a statement has an equality predicate on a non-unique index key, or a non-equality or range predicate on a unique index key. (=, LIKE if not on leading edge).
Index ranges scan descending: Same as Index range Scan but work with order by clause with desc option.
Index unique scan: Only one row will be returned from the scan of a unique index. It will be used when there is an equality predicate on a unique (B-tree) index or an index created as a result of a primary key constraint.
Index skip scan: In order for an index to be used. If all the other columns in the index are referenced in the statement except the first column, Oracle can do an index skip scan, to skip the first column of the index and use the rest of it.
Full Index Scan: A full index scan does not read every block in the index structure. An index full scan processes all of the leaf blocks of an index, but only enough of the branch blocks to find the first leaf block. It’s cheaper than scanning full table.
Index join : This is a join of several indexes on the same table that collectively contain all of the columns that are referenced in the query from that table. No table access is needed, because all the relevant column values can be retrieved from the joined indexes.
Bitmap Index: A bitmap index uses a set of bits for each key values and a mapping function that converts each bit position to a rowid. Oracle can efficiently merge bitmap indexes that correspond to several predicates in a WHERE clause, using Boolean operations to resolve AND and OR conditions.
Fast full index scan: This is an alternative to a full table scan when the index contains all the columns that are needed for the query, and at least one column in the index key has the NOT NULL constraint. It cannot be used to eliminate a sort operation, because the data access does not follow the index key. It will also read all of the blocks in the index using multiblock reads, unlike a full index scan.
Oracle offer several join methods
Hash Joins: Hash joins are used for joining large data sets. The optimizer uses the smaller of the two tables or data sources to build a hash table, based on the join key, in memory. It then scans the larger table, and performs the same hashing algorithm on the join column(s). It then probes the previously built hash table for each value and if they match, it returns a row.
Nested Loops joins: Nested loops joins are useful when small subsets of data are being joined and if there is an efficient way of accessing the second table (for example an index look up). For every row in the first table (the outer table), Oracle accesses all the rows in the second table (the inner table). Consider it like two embedded FOR loops.
Sort Merge joins: Sort merge joins are useful when the join condition between two tables is an inequality condition such as, , or >=. Sort merge joins can perform better than nested loop joins for large data sets. The join consists of two steps: Sort joins operation: Both the inputs are sorted on the join key. Merge join operation: The sorted lists are merged together.
Cartesian join: The optimizer joins every row from one data source with every row from the other data source, creating a Cartesian product of the two sets. Typically this is only chosen if the tables involved are small or if one or more of the tables does not have a join conditions to any other table in the statement.