Create a Multi-Container YAML Manifest for a Pod
In this blog, we will create a build pipeline for a project using a Kubernetes cluster. We will set up a multi-container pod with two containers: one for an HTTP server and another for testing the application.
Create a manifest file for multi-container. I will break the file in smaller section for understanding purpose:
`1. Open vi editor to make a file multicontainer.yaml
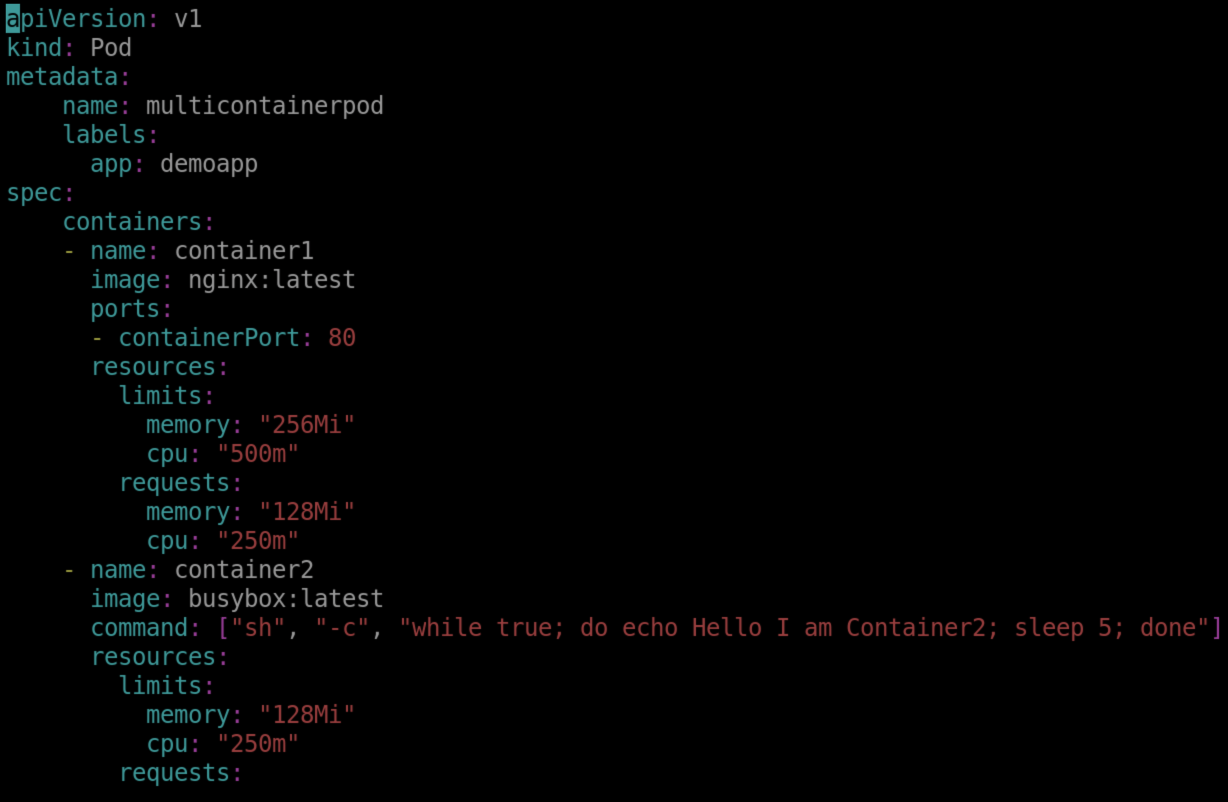
apiVersion: v1kind: Podmetadata: name: multicontainerpod -- is the name of container labels: app: demoapp
2. Create an HTTP server container named container1 using nginx.
spec: containers: - name: container1 image: nginx:latest
3. Specify the ports and memory usage.
ports:- containerPort: 80resources: limits: memory: "256Mi" cpu: "500m" requests: memory: "128Mi" cpu: "250m"
4. Create a new container, container2, to record incoming requests.
name: container2 image: busybox:latest
5. Add a script to show a message confirming it’s from container-2. You will test this in the next challenge.
command: ["sh", "-c", "while true; do echo Hello I am Container2; sleep 5; done"]
6.Specify the resources for container2 as shown below:
resources: limits: memory: "128Mi" cpu: "250m" requests: memory: "64Mi" cpu: "125m"
7. Save the file.
Complete file as:
apiVersion: v1kind: Podmetadata: name: multicontainerpod labels: app: demoappspec: containers: - name: container1 image: nginx:latest ports: - containerPort: 80 resources: limits: memory: "256Mi" cpu: "500m" requests: memory: "128Mi" cpu: "250m" - name: container2 image: busybox:latest command: ["sh", "-c", "while true; do echo Hello I am Container2; sleep 5; done"] resources: limits: memory: "128Mi" cpu: "250m" requests: memory: "64Mi" cpu: "125m"
Run the Kubectl command to apply
kubectl apply -f multi.yamlpod/multicontainerpod created
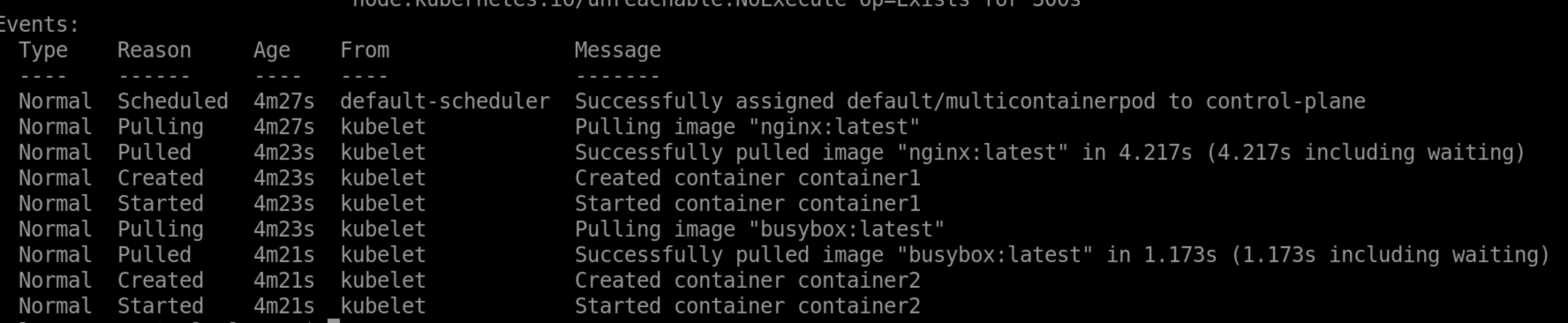
Check the pods
kubectl get podsNAME READY STATUS RESTARTS AGEmulticontainerpod 2/2 Running 0 96s

Check with describe commands
kubectl describe pod